Sự Dịch Chuyển Địa Chấn: Từ "Data Scientist" Sang "AI Engineer" – Bạn Đã Sẵn Sàng Chưa?
Thế Giới AI Đã Thay Đổi – Và CV Của Bạn Cũng Phải Thay Đổi
Mình nhớ năm 2022, khi còn đi phỏng vấn Data Scientist intern, câu hỏi recruiter hay hỏi nhất là: "Em đã train model nào từ đầu chưa?"
Fast forward đến 2025, câu hỏi đó đã thay đổi hoàn toàn:
"Em có kinh nghiệm integrate LLM APIs không? Em đã build RAG system chưa?"
Nếu bạn vẫn đang focus 100% vào việc học Scikit-learn, TensorFlow, và cách train model từ đầu mà không biết gì về RAG, LLM APIs, hoặc AI Agents – mình phải nói thẳng: Bạn đang học skillset của năm 2022.
Không phải những skills đó không còn giá trị. Mà là market đang shift – và shift rất nhanh.
Hôm nay, mình sẽ break down cho bạn thấy:
- Pipeline công việc đã thay đổi thế nào
- Tại sao foundation models làm thay đổi game
- JD năm 2023 vs 2025 khác nhau như thế nào
- Và quan trọng nhất: Bạn cần làm gì NGAY BÂY GIỜ để không bị tụt hậu
1. The Old World (2020-2023): Data Scientist Làm Việc Như Thế Nào
Trước đây, quy trình làm việc của một Data Scientist hoặc ML Engineer trông như thế này:
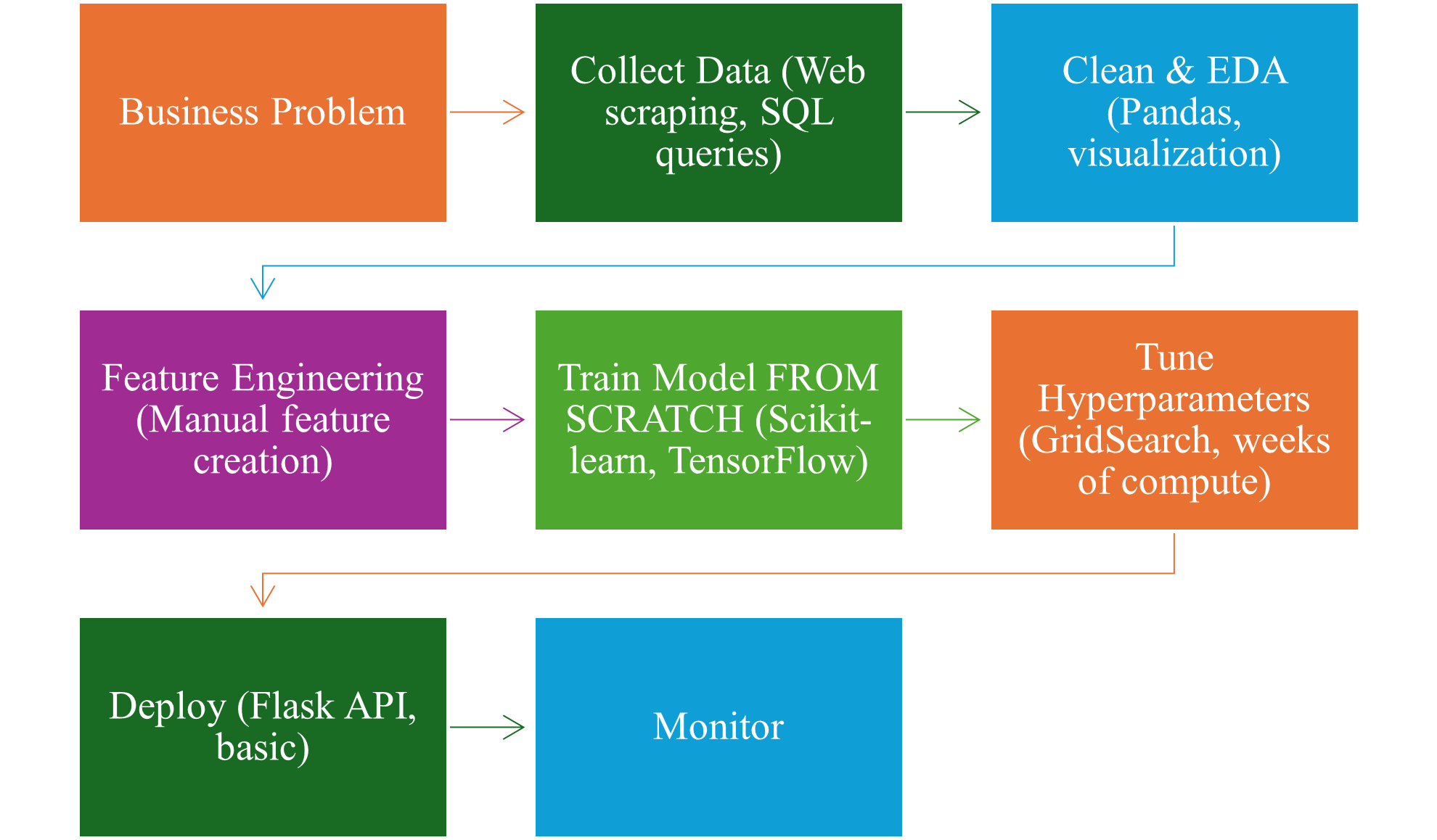
Trong pipeline này, 70-80% thời gian dành cho bước 2-6:
- Thu thập data
- Làm sạch data
- Feature engineering
- Train model
- Tune hyperparameters
Một project điển hình mất 2-3 tháng để đưa model lên production.
Ví dụ thực tế năm 2022:
Công ty muốn build một sentiment analysis system cho customer reviews.
Process:
- Scrape 100K reviews từ nhiều nguồn → 2 tuần
- Clean data, remove duplicates, label → 3 tuần
- Feature engineering (TF-IDF, word embeddings) → 1 tuần
- Train BERT model from scratch → 2 tuần (+ chi phí GPU)
- Tune hyperparameters → 1 tuần
- Deploy → 1 tuần
Tổng: 10 tuần, cost ~$2000 cho compute, accuracy ~87%
2. The New World (2024-2025): AI Engineer Làm Việc Thế Nào
Bây giờ, với sự xuất hiện của Foundation Models (GPT-4, Claude, Gemini, LLaMA), pipeline đã thay đổi hoàn toàn:
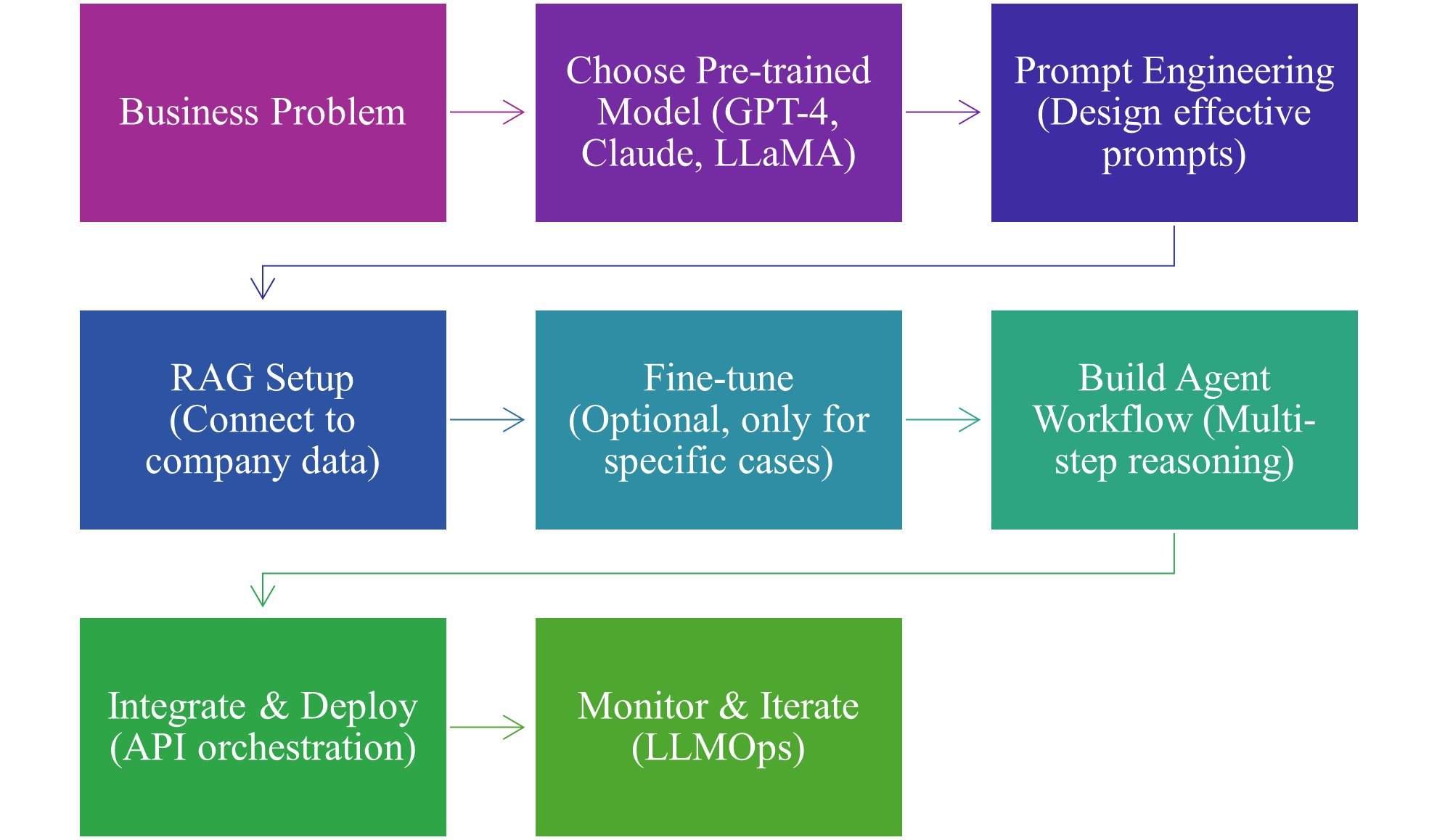
Sự thay đổi cốt lõi:
Bạn không còn train model từ đầu cho mọi bài toán nữa.
Thay vào đó, bạn sử dụng model có sẵn và customize nó thông qua:
- Prompt engineering
- RAG (Retrieval-Augmented Generation)
- Fine-tuning (trong trường hợp đặc biệt)
- Agent workflows
Cùng ví dụ sentiment analysis ở trên, nhưng năm 2025:
Process:
- Setup OpenAI API hoặc Claude API → 30 phút
- Design prompt với few-shot examples → 2 giờ
- Test với 1000 reviews → 1 giờ
- Integrate vào existing system → 1 ngày
- Deploy → 1 ngày
Tổng: 3 ngày, cost ~$50 cho API calls, accuracy ~92%
Bạn thấy sự khác biệt chưa?
• Thời gian: 10 tuần → 3 ngày
• Chi phí: $2000 → $50
• Accuracy: 87% → 92%
3. Tại Sao Thay Đổi Này Xảy Ra? 3 Lý Do Không Thể Phủ Nhận
3.1. Lý do 1: Chi phí compute giảm mạnh + Model quality tăng vọt
Hãy nhìn vào con số thực tế:
| NĂM | TASK | CHI PHÍ | THỜI GIAN | ACCURACY |
|---|---|---|---|---|
| 2020 | Train BERT model | ~$1000 | 3 ngày compute | 85% |
| 2025 | Call GPT-4 API | ~$3 cho 1M tokens | Instant | 92% |
Doanh nghiệp sáng suốt ở chỗ.
Tại sao phải thuê team 3 người, tốn 2 tháng để train một model đạt 85% accuracy, khi họ có thể gọi API GPT-4, viết vài dòng prompt, đạt 92% accuracy trong... 2 ngày?
Câu trả lời: Không có lý do nào cả.
3.2. Lý do 2: Foundation Models đã "học" hầu hết pattern cơ bản
GPT-4 đã được train trên toàn bộ Internet. Nó "biết" về:
✅ Sentiment analysis
✅ Named Entity Recognition (NER)
✅ Text classification
✅ Summarization
✅ Translation
✅ Basic reasoning
✅ Code generation
✅ Question answering
Bạn không cần phải train lại những cái này.
Bạn chỉ cần:
- Biết cách "hỏi đúng cách" → Prompt Engineering
- Biết cách "cung cấp context đúng" → RAG System
- Biết cách "kết nối với data của công ty" → Vector Databases
3.3. Lý do 3: Tốc độ ra sản phẩm (Time-to-market) là vua
Startup không có 6 tháng để bạn train model từ đầu. Họ cần MVP trong 2 tuần.
So sánh value:
👤 Engineer A: Biết train BERT model hoàn hảo trong 3 tháng, accuracy 89%
👤 Engineer B: Biết integrate GPT-4 + build RAG system + deploy lên production trong 2 tuần, accuracy 91%
Câu hỏi: Startup sẽ hire ai?
Câu trả lời rất rõ ràng: Engineer B. Không phải vì Engineer A dở, mà vì market đang ưu tiên speed và practical results.
4. Insight Quan Trọng: Thay Đổi Trong Job Descriptions
Đây là phần mình muốn bạn chú ý nhất. Hãy xem sự khác biệt giữa JD năm 2023 vs 2025:
❌ JD Data Scientist 2023:
Requirements:
- Master's in Statistics/CS
- 3+ years experience training ML models
- Expert in Scikit-learn, TensorFlow, PyTorch
- Deep knowledge of algorithms: SVM, Random Forest, Neural Networks
- Experience with feature engineering and model optimization
- Strong statistical background
- Published research (preferred)
✅ JD AI Engineer 2025:
Requirements:
- Bachelor's in CS or related field (Master's preferred but not required)
- Experience with LLM APIs (OpenAI, Anthropic, or open-source)
- Knowledge of RAG architecture and vector databases
- Familiar with LangChain, LlamaIndex, or similar frameworks
- Ability to design and implement AI agent workflows
- Understanding of prompt engineering and LLM limitations
- Experience integrating AI into production web applications
- Knowledge of LLMOps and monitoring
Phân tích sự khác biệt:
| KHÍA CẠNH | 2023 | 2025 |
|---|---|---|
| Degree | Master's required | Bachelor's đủ |
| Core skill | Train models | Integrate & orchestrate LLMs |
| Tools | Scikit-learn, TensorFlow | LangChain, LLM APIs |
| Focus | Algorithm depth | System design & integration |
| Timeline | Months per model | Days/weeks per product |
❌ Không còn yêu cầu:
- Master's degree (Bachelor's là đủ trong nhiều trường hợp)
- "3+ years training models from scratch"
- Deep knowledge về thuật toán cổ điển (SVM, Random Forest...)
✅ Yêu cầu mới (bắt buộc):
- LLM APIs (OpenAI, Anthropic, open-source alternatives)
- RAG systems
- Vector databases (Pinecone, Weaviate, ChromaDB)
- LangChain/LlamaIndex
- Agent workflows
- Production integration skills
- Prompt engineering
5. Skills Map: Từ Data Scientist Sang AI Engineer
Để dễ hình dung, mình làm một bảng so sánh skills:
| TRADITIONAL DATA SCIENTIST | AI ENGINEER (2025) | STATUS |
|---|---|---|
| Scikit-learn, XGBoost | LangChain, LlamaIndex | 🔄 Chuyển đổi |
| Feature engineering manual | Prompt engineering | 🔄 Chuyển đổi |
| Model training from scratch | Fine-tuning foundation models | 🔄 Chuyển đổi |
| SQL databases | Vector databases (Pinecone, Weaviate) | 🆕 Học mới |
| Pandas, NumPy | Vẫn cần, nhưng ít hơn | ✅ Giữ lại |
| TensorFlow, PyTorch | Hiểu concepts, nhưng ít code | ⚠️ Giảm |
| Statistics, probability | Vẫn cần fundamentals | ✅ Giữ lại |
| Flask/FastAPI deployment | Vẫn cần | ✅ Giữ lại |
| N/A | RAG architecture | 🆕 Học mới |
| N/A | AI Agent design | 🆕 Học mới |
| N/A | LLMOps & monitoring | 🆕 Học mới |
Điều này có nghĩa gì?
KHÔNG CÓ NGHĨA: Bỏ hết đi học LLM CÓ NGHĨA: Bổ sung thêm 40-50% skills mới, giữ 50-60% foundation cũ
Sự Thật Mà Ít Ai Nói: Bạn Không Cần "Bỏ Hết Đi Học Lại"
Có một misconception mà mình thấy rất nhiều: "Ôi, AI thay đổi quá nhanh, mình phải bỏ hết đi học lại từ đầu."
Không phải vậy.
- Foundation knowledge về:
- Python programming
- Data structures & algorithms
- Statistics & probability
- SQL & databases
- Software engineering principles
... vẫn cực kỳ quan trọng.
Điều thay đổi là "top layer" – cách bạn apply những kiến thức đó.
Thay vì:
- Train model from scratch → Integrate pre-trained models
- Feature engineering → Prompt engineering
- Model optimization → RAG optimization
- Deploy Flask API → Deploy LLM orchestration
Core principles không đổi. Tools thay đổi.
Lời Kết: Đừng Sợ Thay Đổi – Hãy Embrace Nó
Mình hiểu cảm giác overwhelming khi thấy mọi thứ thay đổi nhanh đến vậy.
Bạn vừa học xong TensorFlow, vừa build được vài models, vừa cảm thấy tự tin... thì market lại shift sang một hướng khác.
Nhưng đây là sự thật về career trong tech:
Change is the only constant.
Người thành công không phải là người biết nhiều nhất. Mà là người adapt nhanh nhất.
Tin tốt là: Bạn không cần bỏ hết đi học lại.
Foundation bạn đã học (Python, algorithms, statistics) vẫn vô cùng quan trọng. Bạn chỉ cần thêm một layer mới – và layer đó có thể học được trong 30 ngày.
Hẹn gặp lại bạn trong bài viết tiếp theo
Đây là DexTALK – Cùng giải mã mê cung sự nghiệp AI. 🚀
Hashtags: #AIEngineer #DataScientist2025 #RAGSystem #LLMIntegration #AIAgent #LangChain #PromptEngineering #VectorDatabase #CareerChuyenDoi #FoundationModels #DexTALK #GPT4API